Things I Wish I Knew When I Started Building Reactive Systems
This is a summary of the talk „A Pragmatic View of Reactive“ on ScalaDays Amsterdam. If you prefer watching a video, there’s a recording on YouTube. Or if you prefer German, there’s an even longer German version of this on Jaxenter.
The term reactive (as in reactive systems, or reactive architecture) is defined in the Reactive Manifesto. It describes systems that are so elastic and resilient that they are always responsive, and they achieve this through asynchronous message passing. Now this is a fine definition, but as manifestos go, it’s not a pragmatic guide for developers. When you attempt to build reactive systems coming from the world of Java web and enterprise development, you’ll stumble across some fundamental differences and might wish someone had told you earlier. Unless you read this blog post, of course, because I’m going to let you in on four things you should know.
1. You’ll be using a different concurrency model.
On the JVM, our basic concurrency model is the Thread. Why? We run on multi-threaded environments, and the JVM threads map to native threads, and that, at the time people came up with this, seemed a pretty good idea.
Before multi-threading, there was multiple processes. But starting a new process for anything you want to do concurrently is rather heavyweight, plus you need Inter-Process Communication to exchange data between those processes. Threads were introduced as “light-weight processes” that have access to the same memory space, for easy data exchange. There are some problems with this, though.
First of all they are not that light-weight after all. Each thread you start will take 1MB of memory (that’s the default thread stack size on a 64 bit JVM). The maximum number of threads is limited by the operating system and may be your scalability bottleneck, for example if you need to handle thousands of HTTP requests concurrently. And the cost of switching between threads, the context switch, has become relatively high in modern multi-core CPUs with non-uniform memory access, compared to just executing the code of a running thread.
If this wasn’t enough, the shared memory programming model is also not exactly ideal. Concurrent programs with shared mutual state are prone to race conditions, which are notoriously hard to debug. Avoiding this by locking and synchronization can lead to deadlocks, or at least to contention that will hurt performance.

(Slide from John Rose’s presentation JVM Challenges)
So, as JVM architect John Rose said on JFokus 2014 - Threads are passé. Not that they are going away, but as an API for us developers, we need something else, something that gives us sub-thread level concurrency.
Examples for this are the Play web framework, the vert.x framework, the Akka actor toolkit, Project Reactor, and Lagom. All of these have in common that they multiplex tasks (depending on the framework named actions, verticles, actors..) on just a few threads, and thus get by with much fewer context switches. Akka also eliminates shared mutual state, by encapsulating state in actors that only communicate with immutable messages.
In contrast to this, the Servlet API from JEE is based on the thread-per-request model, where each request will grab a thread exclusively while being processed.
The reactive, sub-thread-concurrency of course scales much, much better - see for example “Why is Play so fast” for more background on this.
But just be aware of a pitfall: Some things you might be used to actually rely on thread-per-request. Everything that uses a ThreadLocal to store its data. ThreadLocal in reactive applications is definitely an anti-pattern, as every thread is shared by many tasks (actors, verticles..). slf4j’s MappedDiagnosticContext is an example for ThreadLocal usage, as are Spring Security or Hibernate. All this may not behave as you expect, so you need to let go of it and embrace truly reactive tools, or build workarounds.
You are going to use sub-thread level concurrency. Understand and embrace this.
2. You’ll be using asynchronous I/O (or if you keep using synchronous I/O, it’ll need special treatment).
What’s worse than using too many threads? Blocking threads by using synchronous I/O. In the JavaScript world asynchronous I/O is the standard. node.js showed how you can build efficient server applications running on just a single thread with purely asynchronous I/O. It makes use of the capabilities of modern hardware and operating systems, where I/O is handled by the respective controllers and does not need to use CPU threads.
You’re probably used to doing blocking I/O, using java.io.File, or some synchronous HTTP client. What happens there? While waiting for the result of the operation, the thread will be blocked. As explained in the previous section, a thread is a valuable resource, though. It could continue and do something else, instead of making the CPU switch to another thread. This is particularly bad when you are using a reactive architecture, which relies on the tasks to yield control after a short period of time, in order to achieve the desired effect that few threads handle many, many tasks. You certainly don’t want to block one of those threads - you’ll exhaust your thread pool quickly. So just use asynchronous I/O for everything.
Everything? Well, there are certain cases where you might not be able to. JDBC is an example for that. Non-blocking JDBC is pretty far in the future, so for now, you’re stuck with blocking JDBC. The only way you can integrate this properly into a reactive system is to keep it away from the rest. You need to define a separate thread pool for synchronous I/O, so that your threads for CPU bound work, which process the tasks, are not affected. All reactive frameworks have some facility for this. In Play and Akka you can define separate dispatchers, in vert.x you have worker verticles, etc.
You don’t want to use blocking I/O. Use non-blocking I/O, and if you really can’t (e.g. if you need to use JDBC), then isolate blocking calls by using a separate thread pool.
3. There’s no Two-Phase-Commit
This is something that could easily fill multiple blog-posts alone, so we can only touch the surface of this.
What if we don’t only have a database access, a JDBC call where we do a select as in the previous example? Look at this little code snippet:
public class GreetingService {
@Inject
private JmsTemplate jmsTemplate;
@PersistenceContext
private EntityManager entityManager;
@Transactional
public void createGreeting(String name) {
Greeting greeting = new Greeting(name);
this.entityManager.persist(greeting);
this.jmsTemplate.convertAndSend("greetings", greeting);
// ...
}
}
Here, we have two transactional systems, a message queue and a database, within one transaction. In this case (this is some Spring Framework example code) that’s really easy: I have to define a transaction manager somewhere. If I have a transaction manager that’s capable of handling distributed transactions, this code is all I have write to get the “all-or-nothing” logic.
How could I achieve this in an asynchronous system, where I even want avoid blocking I/O? The answer is: You don’t want to.

(Slide from Pat Helland’s presentation Life Beyond Distributed Transactions)
If you can, avoid it. Think of the reactive traits - we want to be elastic and resilient. The whole concept of a synchronous 2-phase-commit is not made for that. In the Oracle Transaction Manager documentation it says: “the commit point should be a system with low latency and always available“. Because it will easily break if one of the involved parties isn’t. It doesn’t account for the ability of the systems to fail. And the unavoidable latency will hold you back as well. It’s a natural point of contention and failure. If you look at existing highly scalable systems, people don’t use distributed transactions.
I’ve seen things like the above snippet, a message queue and database access, in real world projects. It’s not the worst use case for a distributed transaction, but also an example for a two-phase commit that could be avoided. The goal of the transactional bracket is to provide “all-or-nothing” - you want either both things to complete successfully, or none of them. But here, you don’t have any control over the receiving end of the queue. The processing of the message at the receiving end might still fail. This example is really about system reconciliation - you want the system state at the other end of the queue to catch up with your database eventually. But this could be handled in a completely asynchronous fashion, without the need for any 2-phase-commit.
If you encounter a requirement for a distributed transaction, the first step should be to challenge it. Actually, the second and third step, too. Try to avoid it. Challenge the requirement: Is the “all-or-nothing” really necessary, or did someone just think it’s easy to do? The best solution is to define the business processes so that distributed transactions are not required. Often, this is not even about changing the business process, but about discovering that it’s not really a business requirement and only got in there because some assumptions were made, e.g. that a central, relational database would be used.
Still, I can’t rule out completely that you might encounter a situation where you genuinely need the “all-or-nothing” semantics. But you can still avoid a 2-phase-commit. The basic idea behind this is that you can achieve the same effect with asynchronous messaging. A principal explanation of this is given in the paper “Life Beyond Distributed Transactions” by Pat Helland. (A really good paper, by the way. Quote: “Grown-Ups Don’t Use Distributed Transactions”. And “Distributed transactions don’t scale, don’t even try to argue with that, just believe that.”).
It’s not trivial, though. You need “at-least-once delivery” for your messages (btw. that’s not the standard if you use plain Akka, which only gives you “at-most-once delivery”. But extensions to provide “at-least-once” are available). Also, as you can’t guarantee message order, you need idempotent messages, or some way to handle out-of-order messages and multiple deliveries. And lastly, you have to have some “compensation ability”. I.e. you have to have an idea of a tentative operation. Think of a hotel reservation which you either have to confirm (possibly by payment) within a certain time, or it’s cancelled. The reservation is the tentative operation, and it’s either committed or rolled back. So there’s no mechanical rewriting of 2-phase-commits into asynchronous messaging - it will affect your modeling. You’ll have to think about the messaging you do, and about your process. But it should be possible.
An application of this general approach is the Compensating Transaction Pattern, or Saga Pattern. In this pattern, you start a Saga, and each of the steps has a counterpart that will reverse the operation.
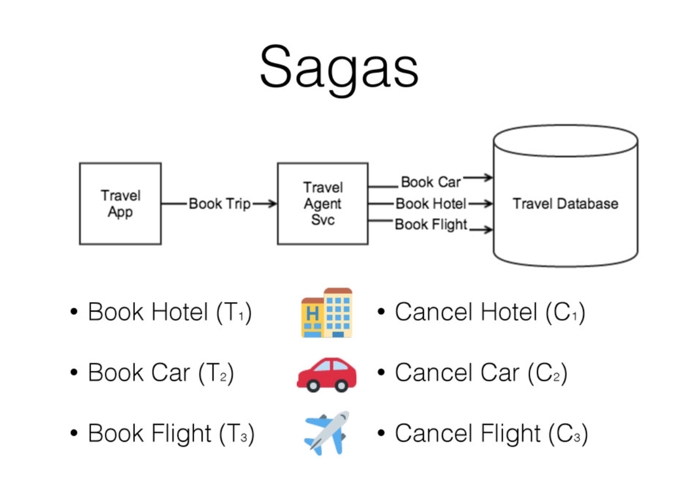
(Slide from Caitie McCaffrey’s presentation Applying The Saga Pattern)
So the transaction will be to book the hotel, and the compensating action would be to cancel the hotel. You book the car, you cancel the car, you book the flight, you cancel the flight.
Again, implementing this is not trivial. This is not “built-in” in for example Akka. You need to implement a Saga Coordinator which takes care of recording these actions, and makes sure that either the whole Saga is successfully completed, or the appropriate compensations are executed. It’s needs a durable log, the Saga Log. And again you need “at-least-once-delivery”. You must guarantee that the compensating message will be delivered at least once, otherwise you can’t guarantee the all-or-nothing rule.
There is much more to be said about this, but we’ll stop here. The bottom line is: Distributed transactions are a source of contention and of failure, you should definitely avoid them. Local transactions are fine, and the Compensating Transaction Pattern is a pragmatic solution for having an “all-or-nothing” approach in a distributed world.
Another article I recommend on this topic as a whole is “Distributed Transactions: The Icebergs of Microservices”.
Don’t use distributed transactions.
4. There’s no Application Server
Reactive applications don’t use application servers. Reactive applications are deployed as standalone applications. (I used to call this “containerless”, because of servlet containers. But now if I say containerless, people think I argue against Docker. It’s not about containerization and Docker (which are fine), it’s about servlet containers and application servers (which are not)).
So what’s the issue with application servers? From a technical point of view, if you use a Java EE application server (or servlet container - I use the terms interchangeably in this section, as the criticism applies equally to both), you’re going to use the Servlet API. This API is - barring some recent additions that haven’t really become popular so far - a synchronous API. The Servlet API is built for the thread-per-request model, which puts unnecessary limits on the scalability (see the first section above).
In case you missed the memo... App Servers / Service Containers are dead. OS Containers + Container-less Apps are the future.
— James Ward (@_JamesWard) September 12, 2014
Another reason is the lack of benefit we get from an application server. It adds complexity and costs. I have to buy it, I have to install it, I have to operate it. What does it give me? Some APIs.
The original idea was to have a container where I can put in a number of services - I put in a couple of .wars or .ears for different applications. Many people don’t use them that way. The value of isolation (of isolating your applications so that a crash of, or high load on one, will not affect others) is higher than the value of being able to deploy a couple of applications on one server.
What people do is, they run exactly one application per application server instance. You’d rather start a couple of Tomcats with one application in it, than one Tomcat with ten applications in it.
If you only deploy one application per server - then, what the server really becomes is just a library that you add to your application! Different is only the packaging. Instead of delivering a .war, you could just bundle the “server” with your application and deliver a .jar. (This is what Spring Boot does. Spring Boot just gives you a standalone .jar that you can run, and it just puts the Tomcat (or the Jetty, or the Undertow) in there). Some good reading on this is “Java Application Servers Are Dead”: Part1, Part2, Presentation.
So, if it’s just a library, instead of bundling what used to be the server as a dependency, you could just as well use any other library that handles HTTP. That’s what Play does, it relies on the asynchronous netty library, skipping the Servlet API altogether.
Application servers have a lot of tooling built around them, and operations people tend to like that. But there are other tools nowadays that you can use to conveniently deploy small services and operate them, service orchestration tools such as Kubernetes, Docker Swarm, or ConductR.
tl;dr When you build a Reactive System
- You’re going to use sub-thread level concurrency
- You want to use asynchronous I/O. If you can’t, at least isolate any synchronous I/O (JDBC) from the rest.
- You don’t want to use distributed transactions, they’re fragile, they’re points of contention.
- You don’t want to use an application server.
